


In modern data management, businesses have diverse needs for balancing reliability, availability, and cost. To meet these requirements, TDengine introduced two enterprise-grade solutions in version 3.3.0.0: the Active-Active and the Arbitrator-based Double Replica solutions. These solutions cater to different application scenarios, providing robust data storage and management options. This article will dive into the use cases, technical features, and best practices of these two solutions, offering insights into how they help enterprises achieve success in efficient and reliable data management.
TDengine Dual Replica (+Arbitrator)
To address the need for cost-effective deployments without sacrificing reliability and availability, TDengine has developed the Dual Replica solution with an Arbitrator. This solution offers fault tolerance, with the ability to handle a single service failure without causing data loss, making it a great option for businesses looking to reduce costs while improving efficiency.
Compared to traditional triple-replica databases, the dual replica database offers significant advantages. It reduces hardware costs while still ensuring high availability. Specifically, each Vgroup in a dual replica setup has only two Vnodes. If one Vnode fails, the Mnode can use the data synchronization status to determine if the other Vnode can continue to provide service. This mechanism ensures no data loss during a node failure and enables the system to continue processing ingestion and queries.
This solution is ideal for customers looking to lower storage costs, reduce physical node requirements, and with slightly lower high-availability needs.
From a technical perspective, the dual replica solution offers the following key features:
- Replica Count: Each time-series data replica count is set to 2, but the total number of nodes in the cluster must be 3 or more.
- Automatic Leader Election: If a Vnode fails, the system can automatically switch the leader to ensure data remains available and the system can continue to operate without interruptions.
- Leader Election Mechanism: The leader election in the dual replica setup is managed by the high-availability Mnode instead of the Raft protocol.
The Arbitrator plays a crucial role in the dual replica setup. It provides arbitration services without storing data. If a Vnode in a Vgroup fails and can no longer provide service, the Arbitrator determines which remaining Vnode becomes the “Assigned Leader.” This ensures that even if some replicas are down, the system can continue to serve requests and maintain high availability.

TDengine Active-Active Solution
For some users, especially those with special deployment requirements, the Active-Active solution offers a way to maintain high availability and data reliability with just two servers. This solution is ideal for environments with limited resources or scenarios requiring disaster recovery between two TDengine clusters.
In the business system, an Active-Active architecture usually consists of two servers, each running a complete set of services. These servers are often referred to as primary and secondary nodes.
The Active-Active solution is especially useful in the following scenarios:
- Limited Deployment Environments: Customers with resource constraints who still require high availability and data reliability.
- Industrial Control Systems: These systems have extremely high reliability and data accuracy requirements, making the Active-Active architecture a good fit.
- Disaster Recovery: Active-Active can be used effectively for disaster recovery between two TDengine clusters, whether the environment is resource-constrained or has no node limitations.
This solution achieves high availability and data reliability through several technical mechanisms:
- Failover: The system uses Client Drivers to automatically failover from the primary node to the secondary node in case of a failure, ensuring continuous service.
- Data Replication: The
taosXfeature replicates data from the primary node to the secondary node, using special markers in the Write-Ahead Log (WAL) to ensure proper data syncing. - Data Filtering: The read interface filters out data with special markers to prevent duplicate entries and infinite loops.
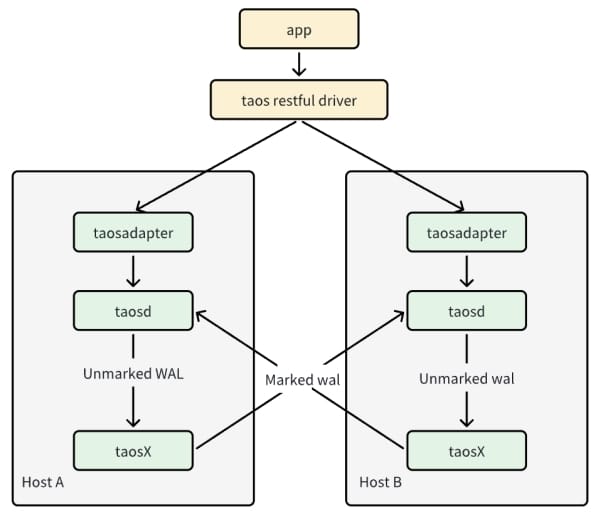
Currently, the Active-Active solution supports JDBC connectors and WebSocket connections but does not support Native connections. Both clusters in an Active-Active setup must be identical in terms of database name and configuration to ensure proper operation.
Dual Replica vs. Active-Active: Differences and Practical Applications
Although both the Dual Replica and Active-Active solutions aim to enhance data reliability and service availability, they have significant differences in architecture and use cases. Understanding these distinctions is crucial for selecting the right solution and implementing it effectively.
- Cluster Architecture: The Active-Active solution requires two independent clusters, each with flexible node configurations, while the Dual Replica solution requires a single cluster with at least three nodes. This gives Active-Active more flexibility but also increases deployment and management complexity.
- Synchronization Mechanism: The Active-Active solution relies on
taosXfor data synchronization, which usually operates on a second-level delay. In contrast, the Dual Replica solution uses an Arbitrator for leader election and the Raft protocol for data consistency, ensuring minimal synchronization latency. - Data Security: In terms of data security, the Active-Active solution depends on the WAL retention duration, while the Dual Replica solution ensures no data loss.
- Availability: The Active-Active solution can continue to operate as long as one node is alive, while the Dual Replica solution might not be able to provide service if only one node is left after consecutive failures.
Best Practices for Dual Replica
- New Deployment: For new deployments, the Dual Replica solution offers a great way to reduce storage costs while maintaining high availability and reliability. A recommended configuration would include:
- A cluster with N nodes (where N ≥ 3)
- N-1 dnodes are responsible for storing time-series data
- The Nth node does not store or read time-series data, meaning it doesn’t hold replicas; this can be achieved by setting the
supportVnodesparameter to 0 - The dnode that doesn’t store replicas consumes fewer CPU/Memory resources, allowing it to run on lower-spec servers
- Upgrading from Single Replica: If upgrading from a single replica setup, expand the cluster to at least 3 nodes and modify the Mnode replica count to 3. Then, use the
ALTER DATABASE REPLICA 2command to adjust the replica settings for specific databases.
Best Practices for Active-Active
The Active-Active system synchronizes data between two systems through data replication, but this synchronization only guarantees eventual consistency, not real-time consistency. The primary node may fail at any time, potentially causing data discrepancies, especially with metadata. After a failover, the business layer might trigger repeated table creation requests, but if the schema differs, it can lead to metadata inconsistency. Therefore, it’s recommended to complete all database and table creation operations during system startup and only ingest time-series data afterward, minimizing further metadata changes.
Conclusion
Both the Dual Replica and Active-Active solutions provide powerful data storage and management options for TDengine users. The Dual Replica solution is an excellent choice for reducing storage costs while ensuring high availability and reliability, making it ideal for enterprises with limited resources. The Active-Active solution, with its flexible architecture and disaster recovery capabilities, is perfect for environments that require high availability and reliability. By understanding the differences and best practices of these two solutions, users can choose the most suitable option to leverage TDengine’s technological advantages and build stable, efficient database systems.



