
High cardinality of data sets has traditionally been a major issue for time series databases (TSDB). Some database management systems perform well when cardinality remains low but become increasingly slow as cardinality increases, forcing database administrators to jump through various hoops in attempts to reduce cardinality manually or to unnecessarily scale out their systems. TDengine is the first time series database to resolve the issue of high cardinality, and this article gives some background into how this was accomplished.
What Is High Cardinality?
To begin, cardinality can be defined as the number of unique values in a data set. The cardinality of a data set can be low or high. For example, Boolean data can only be true or false, and therefore has a very low cardinality of 2. On the other hand, a data point like a unique device ID could have extremely high cardinality: in a deployment with 100 million smart devices, the cardinality of the unique device ID would be hundreds of millions.
For time-series data, things become more complicated. Time-series data is always associated with metadata — a number of tags or labels. The cardinality of a system is therefore the cross-product of the cardinality for each tag. For example, imagine a smart meter that is associated with device ID, city ID, vendor ID, and model ID. With millions of devices across hundreds of cities created by dozens of vendors each having several models, it’s easy to see how the cardinality of the data set can easily exceed 100 billion.
High cardinality increases the time required to locate a unique value, and for a standard database, latency is directly correlated to cardinality. Many time-series databases, like InfluxDB, OpenTSDB, and Prometheus, adopt a key-value storage model in which the key is uniquely identified by the combination of tags. An unfortunate side effect of this model is that it drastically increases the cardinality of data sets. For example, imagine that a “user type” tag is added in the previous smart meter example, with four possible values (enterprise, SME, single-family home, and apartment). This immediately increases the already high cardinality of the data set by a factor of 4 — at least 400 billion.
TDengine makes use of several approaches to solve the high cardinality issue.
Data Model: One Table per Data Collection Point
TDengine has a very specific data model in which a separate table is created for each data collection point (DCP). In the TDengine model, a DCP refers to a piece of hardware or software that collects one or more metrics based on preset time periods or triggered by events. In some cases, an entire device may be a single DCP, but more complex devices may include multiple DCPs that each collects data independently with different sampling rate.
TDengine then uses a consistent hash method to determine which virtual node (vnode) is responsible for storing the data for a specific table. Inside the vnode, an index is built so that the table can be found quickly. As you add DCPs to the system, TDengine creates more vnodes to minimize the latency to locate a table and support scalability.
This design guarantees the latency to insert data points into or query data from any single table even as the number of tables increases exponentially, from one million to 100 million. Thus latency is not affected by high cardinality in TDengine.
Separating Metadata from Time Series Data
By using the one table per data collection point design, TDengine can guarantee the latency for one single table. But real-world analytics use cases require the aggregation of data from multiple tables or devices. This is a major challenge for the TDengine design.
To solve this issue, TDengine introduces the supertable. Unlike a standard database, supertables allow applications to associate a set of labels to each table. TDengine stores those labels independently from the collected time-series data: a B-tree is used to index the labels and store them in the metadata store, while time-series data is stored in a unique time-series data store. Each table in the metadata store has only one row of data, and this row can be updated as needed. In the time-series data store, however, each table has many rows of data, and the data set grows with time until its lifetime has elapsed.
To aggregate data from multiple tables, the application specifies a filter for the labels, for example, calculate the power consumption for “user type” = “single family homes”. TDengine first searches the metadata store and obtains a list of tables that satisfy the filtering conditions, and then it fetches the data blocks stored in the time-series data store and finishes the aggregation process.
By first scanning the metadata store, whose data set is much smaller than the time-series data store, TDengine can provide very efficient aggregation. The process is shown in the following figure.
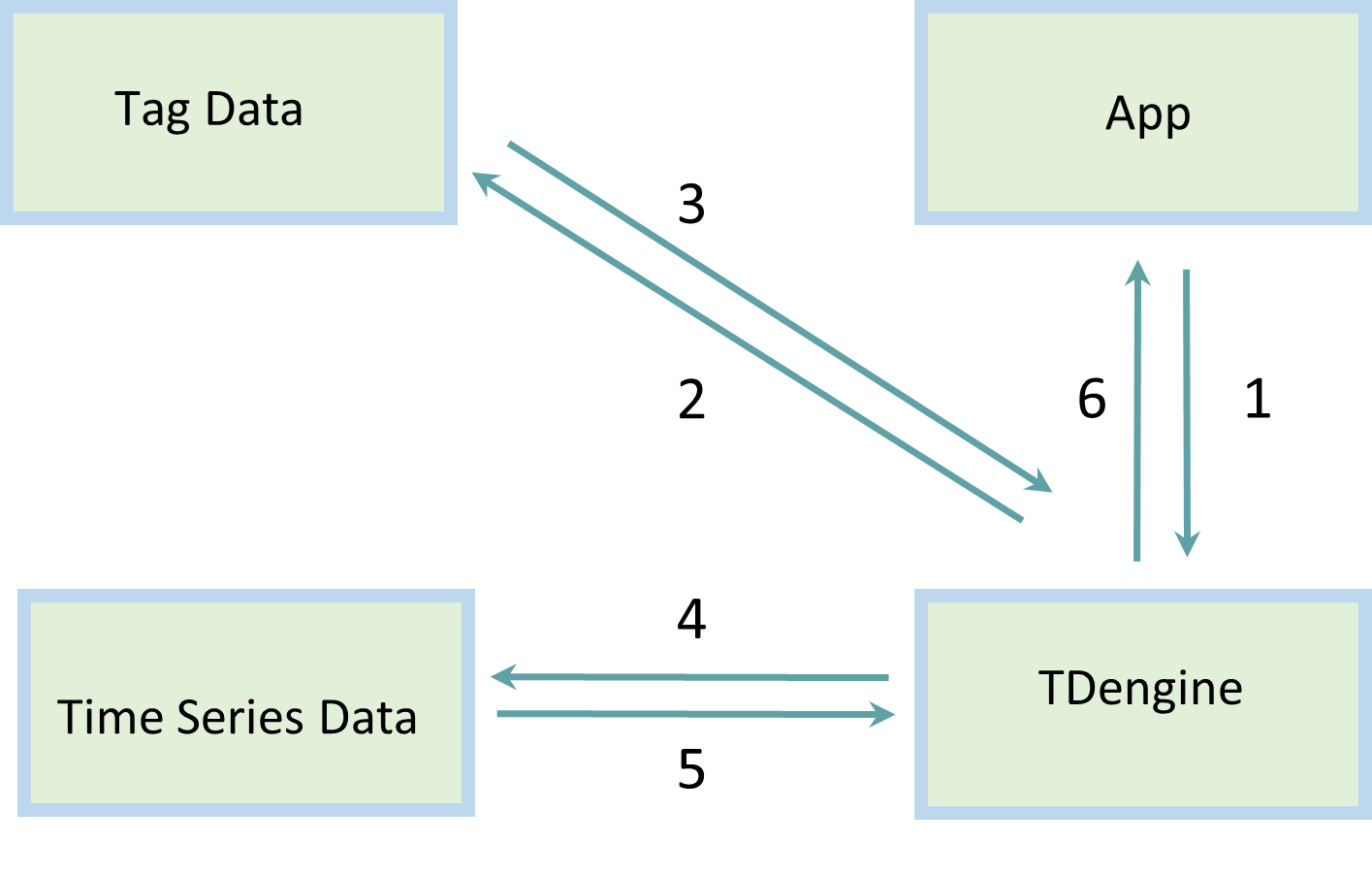
Distributed Design for Metadata Store
In the TDengine 2.x design, the metadata for tables, like schema and tags, were stored on the management node (mnode). This became a key issue for TDengine in deployments that exceed 10 million tables: the latency for filtering this many labels increased and could no longer be guaranteed.
In TDengine 3.0, metadata storage is distributed among vnodes instead of being centralized on the mnode. When an application wants to aggregate the data from multiple tables, TDengine sends the filtering conditions to all vnodes simultaneously. Each vnode then works in parallel to find the requested tables, aggregate the data, and finally send the results back to the query node or driver where the merge operation is performed.
The distributed design of TDengine 3.0 now guarantees latency for label filtering operations provided that system resources are sufficient, and the mnode is no longer a bottleneck. As the number of tables in a deployment increases, TDengine can simply allocate more resources and create more vnodes to ensure the scalability of the system.
Comparison with Other Time-Series Databases
As many developers in the industry know, high cardinality has historically been a major issue for InfluxDB. For more information, Timescale has an in-depth technical article that analyzes the situation.
To prevent high cardinality from affecting performance, TimescaleDB and TDengine have adopted a similar design in which metadata is separated from time-series data. Thanks to the supertable concept, explicit JOIN operations are not required in TDengine, whereas TimescaleDB applications do need to apply JOIN between label data and time-series data explicitly.
However, the main difference between the two models is that TimescaleDB continues to store all labels in a central location. This means that a high enough number of devices will still cause TimescaleDB deployments to suffer from the effects of high cardinality. A distributed design for metadata storage is the only way to solve this problem once and for all. This could be a custom designed metadata store like TDengine uses or something as simple as a distributed SQL database running inside the system to handle metadata.



