
A power station operator created an operations system known as SmartOPS to monitor its plants. However, the hardware of the servers located in their power plants were limited, typically with the following specifications:
- CPU: Intel Atom N2600 1.6 GHz
- Memory: 2GB DDR3 SDRAM
- Display: DB15 VGA Interface
- Storage: one Type I/II Compact Flash, two SATA DISK Interface
The operator decided to deploy a time series database (TSDB) to make the best use of their limited resources and enable data collection for their operations system.
Technical Selection
The overall selection requirements involved many aspects:
- Performance: Read and write performance
- Storage: Compression rate
- Features: Scalability, high-availability, ease-of-use, security,
- TCO: Maintainability, administration, training, service and support.
Their team focused on evaluating the following databases:
- OpenTSDB: With HBase as the underlying storage, it encapsulates its own logic layer and external interface layer. This architecture can make full use of the features of HBase to achieve high data availability and good write performance. However, compared with a native time series database, the OpenTSDB data stack is more complex, and there is still room for further optimization in terms of read and write performance and data compression.
- InfluxDB: Currently it is the most popular time series database. Data is stored in columns, which can efficiently process, store, and query time series data, and provides a feature-rich Web platform that can visualize and analyze data.
- Apache IoTDB: A distributed time series database specially designed for the Internet of Things. Data is stored in columns, with excellent write performance and rich data analysis functions, and can effectively handle out-of-order data.
- TDengine: A distributed time series database specially designed and optimized for IoT and Big Data. Data storage is optimized for memory and disk with extremely high write performance and rich SQL-based, non-proprietary query functions. It also provides full-stack functionality for IoT and Big Data such as caching, stream processing, and message queues, native clustering. The installation package is less than 10MB and the performance improvement of 10 times is indeed very attractive.
- ClickHouse: A powerful OLAP database, data is stored in columns, with extremely high data compression ratio, high write throughput and high query performance. It provides a wealth of data processing functions to facilitate various data analysis.
Based on the fact that localized deployment on the site required lightweight resource consumption, they first excluded OpenTSDB and Apache IoTDB. OpenTSDB is based on HBase and is relatively heavy, while Apache IoTDB is not friendly to edge lightweight devices in terms of resource consumption. While ClickHouse is fast for a single table, it is weak in other aspects, including joins, management and operation and maintenance, which are more complex.
The team finally settled on testing InfluxDB and TDengine.
Preliminary Testing
First, InfluxDB was deployed. At the test power station site, the number of records written per minute is less than 3000 and the resource consumption is shown in the figure below. The CPU consumption of InfluxDB increases but the memory resources do not change much.

A query is executed as follows:

The corresponding resource consumption for the above query is shown in the following figure:
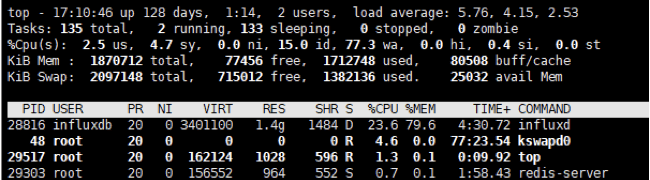
Eventually the query fails without providing any results and so for the current resources, the resource consumption of InfluxDB is too high. The functionality needed for the operator’s system simply could not be provided.
The team then moved on to test TDengine. When just deployed, its resource consumption was as follows:
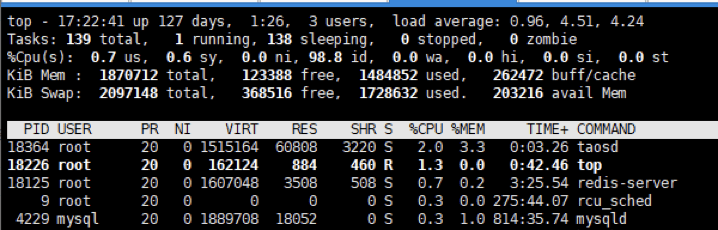
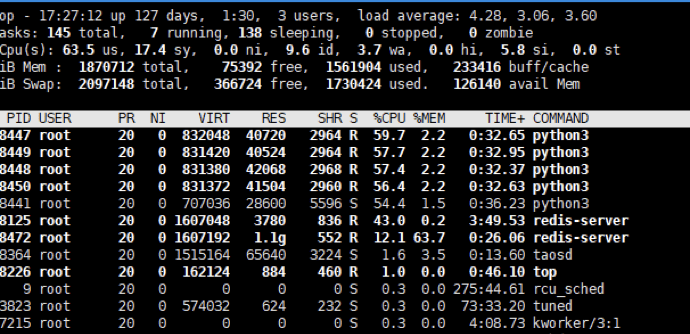
They then tested the same query as above, under the same conditions, and while TDengine has a small increase in the CPU for a short time, the query returns results in milliseconds.
From the above preliminary tests, it is clear that in the case of deployment on low server resources, compared with InfluxDB, TDengine has obvious advantages. For power station systems with very limited resources, TDengine can cope much better and provides a cost-effective solution.
Since TDengine is purpose-built for IoT applications, it capitalizes on the fact that IoT applications have:
- few to no data updates or deletions
- no transaction processing is required like traditional databases
- there is more writing and less reading than Internet applications
TDengine has novel concepts such as “one table per device” and the supertable, which simplify the data storage structure and significantly improve the efficiency of aggregation queries. These are very important for the requirements of energy storage scenarios with limited power station resources.
TDengine Architecture
The data format returned by the power station equipment is basically fixed, with one timestamp and one value, so one supertable was created for each station. Within those supertables, a subtable was created for each device in the plant. Five tags were specified on the supertable — point identification, station ID, substation ID, unit ID, and equipment ID.
To demonstrate the difference in performance between InfluxDB and TDengine, the operator ran the equivalent of the following query on InfluxDB after running and acquiring a week’s worth of data.
<code>select * from ops WHERE ts>1629450000000 and ts<1629463600000 limit 2;To execute the query on InfluxDB, the memory usage rate reached 80%, and no results were returned even after ten minutes. On the other hand, after using TDengine for nearly a month, the same query returned in only 0.2 seconds.
TDengine in Practice
The technical teams at this operator have now adopted TDengine as the core time series database for the station control unit (SCU) architecture. This architecture provides comprehensive information, local operational control and coordinated protection functions for the energy storage system. Data analysis and operations optimization provide the highest level of safety for power stations, and TDengine’s high-performance writing and aggregation query functions provide millisecond-level response to monitor power stations effectively.
In terms of storage, TDengine also excels at data compression. When InfluxDB was being tested, the data volume in one day was more than 200 MB. After switching to TDengine, the data volume in one day, for the same number of collection points, was less than 70 MB, which is 1/3 of the requirements of InfluxDB.
In future projects, the operator plan to use TDengine’s native distributed cluster capability to fully digitize the operation of their power stations. By combining analysis algorithms, prediction algorithms, and data mining algorithms, they aim to provide stability, efficiency and loss analysis, thermal management as well as diagnostic capabilities such as failure prediction and pinpointing performance issues.



