
The TCL energy management platform collects and dynamically monitors several resources in real-time. These include electricity, water, natural gas, oil and other resources and metrics. The platform then calculates energy savings and costs along several dimensions such as time, workshop, production line type, production line, and equipment. It also helps with auditing, industry standard benchmarking, and reporting to help with energy conservation and management. The platform is also a safety platform and can monitor energy safety data and send alarms and information to safety management personnel.
“G-Things” is the IoT platform of our application intelligence platform product family. Let’s first take a look at the data flow on this platform.
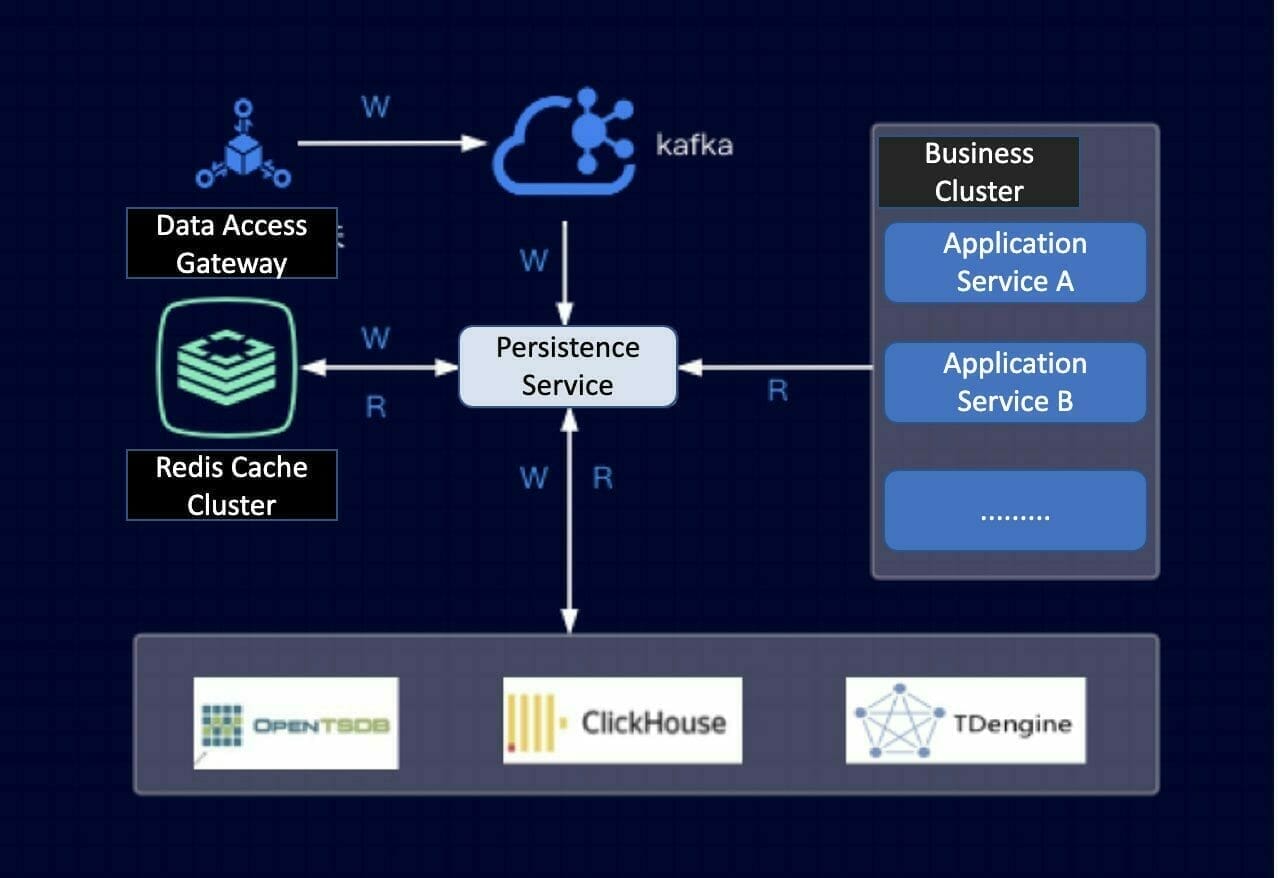
Industrial devices transmit data to the platform data access gateway. The gateway parses the packets, filters out illegal data packets and sends the data to the Apache Kafka message middleware for real-time processing and persistence. The persistence service layer writes the latest data to Redis and persists the data to the appropriate Time-Series Database (TSDB) depending on the application. Note that the platform storage architecture design supports the switching of time series databases such as OpenTSDB, ClickHouse, and TDengine. The database is selected beforehand depending on business needs and requirements.
Storage Engine Selection
Since our architecture allows us to choose between 3 TSDB’s, we went about the choice in the following way.
Firstly, we took a look at the characteristics of the data:
- Timing of data: devices continuously generate data, which is reported to the platform with timestamps.
- Stable data flow: the reporting frequency is relatively stable, and the collection frequency is once every 30 seconds.
- The data is of numerical type and data also needs to be looked at cumulatively and in aggregate across devices.
- There is no change in the data: the data is the collected data recorded at a certain time, and there is no need to update or delete it.
- The aggregation and analysis of data are based on the time dimension and the spatial dimension: the time dimension includes year, month, week, day, and hour, and statistics are performed every 15 minutes at the shortest. The spatial dimension includes manufacturers, workshops, production line types, production lines, equipment.
- Large amount of data: More than 100 million pieces of data are collected every single day.
Based on the data characteristics we have to choose among the three time series database storage engines supported by the platform: OpenTSDB, ClickHouse and TDengine. Here is a comparison:
- OpenTSDB : Relies on HBase, HDFS, ZooKeeper and other components. The hardware resource requirements are high and the cost is high. When the query time span is large, the performance drops sharply. Support for aggregate analysis queries is not adequate.
- ClickHouse : Our requirements are met in terms of data storage, large time-span queries and aggregation queries. However operation and maintenance costs are too high and scalability is too complicated and cumbersome and computing and storage resources used are too high.
- TDengine : It meets our needs in terms of data storage, data analysis and query capability and performance. Additionally the cluster version is also open source, supports horizontal expansion, takes up fewer resources, and is the best choice for storage engines for customers who want to consume fewer resources and reduce costs.
While we conducted more due diligence than the above summary, we ended up choosing TDengine for our project.
Time Series Database Modeling
TDengine has two very novel innovations. The first one is that there is “one table for one data collection point ” and the second one is the idea of a supertable. When designing the data model, it is necessary to consider how the business model is mapped to the supertables and specific tables. Let’s look at the supertable first. Since a supertable corresponds to a type of data collection point, we will create a supertable for each type of data collection point such as electric meter, water meter, petroleum gas meter, and oxygen meter. Using the electric meter as an example:

Let’s look at the normal table. Each data collection point needs to have its own separate table. Like a standard relational database, a table has a table name and schema, but in addition, it can have one or more tags.

TDengine in Practice
The system has been running smoothly since it was launched over six months ago. There have been several advantages to using TDengine. Firstly the hardware and energy resources consumed are dramatically lower. For example, compared to the TCL electronic industry IoT platform that uses ClickHouse as the TSDB, the server needed for TDengine is half the size of that used for ClickHouse even though the amount of data in the two systems is similar. The system also has visualization for both monitoring and real-time queries for all the types of devices. The system is now a comprehensive digital energy management solution and has improved operational decision making. With thorough analysis of electricity, water, oil and natural gas consumption, the energy usage can be optimized and energy consumption has been reduced by about 5%.
There are other noteworthy points that I wish to summarize in our experience with TDengine. TDengine provides a cache of the last record, and real-time data can be quickly obtained through the last_row function. Before using TDengine, the system had to use Redis to cache the latest data, and large amounts of writing to Redis had an impact on performance. Now we can use TDengine cache instead of Redis cache without impacting performance and while simplifying the system. TDengine’s technical experts also provided a lot of support during the process. TDengine has convenient and active technical support groups on social media and besides community support, technical questions are usually answered by experts from TDengine and the response is very fast.



