
Long query issues arise when processing large, time-consuming queries in a database that handles concurrent writes and queries. These long queries can monopolize system resources, leading to potential write blockages. Sometimes, the failure to call resource release functions in query code can also manifest as long query problems. Ensuring that long queries execute correctly without hindering data writes is a challenging problem.
Introduction
While most time-series data use cases may not frequently encounter this issue, it can be quite troublesome when it does occur. To address this, the TDengine development team has been continuously optimizing the system to improve query performance and response speed. This article delves into this challenge and explores how to tackle and resolve long query issues to enhance TDengine’s performance in complex query scenarios.
Data Write/Read Mechanism
Before analyzing the long query problem, it’s essential to understand TDengine’s concurrent write/query mechanism.
Data Write Mechanism
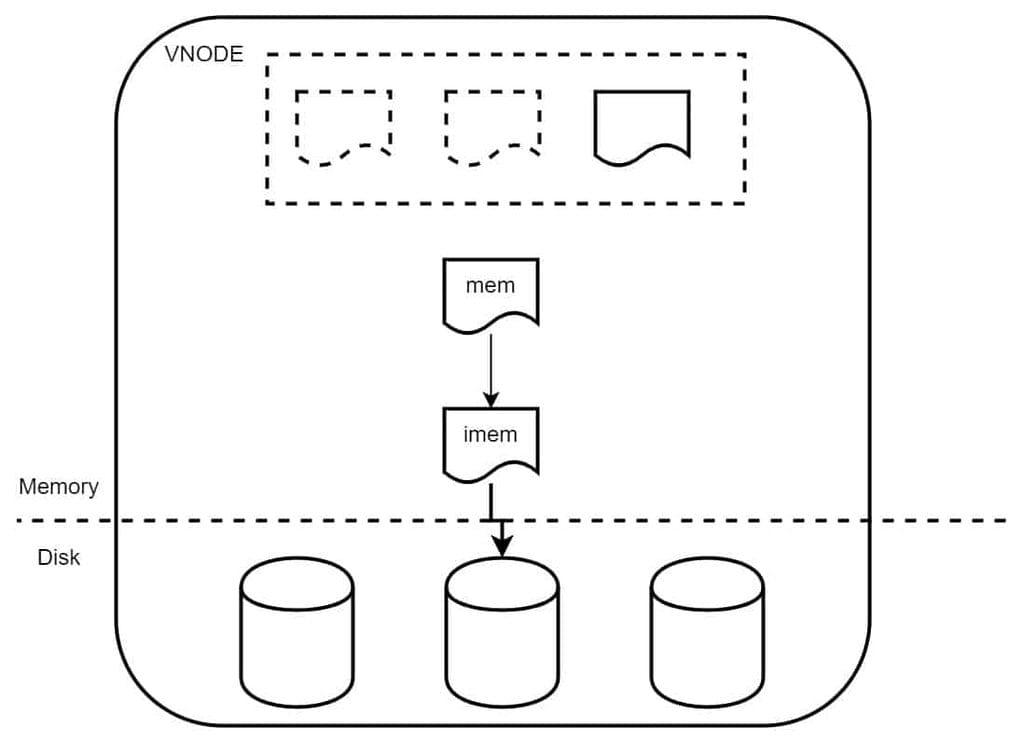
In TDengine, a Vnode (Virtual Node) is the basic unit for storing and querying data. Here’s an overview of its write mechanism:
- Each Vnode is allocated a certain amount of memory based on DB parameters upon creation.
- This memory is divided into three blocks within the Vnode.
- Each Vnode has a single write thread.
- During data writing, the Vnode allocates a memory block from the free list for data writing.
- Once the data exceeds a certain amount in the memory block, it is written to disk, and a new memory block is allocated for further data writing.
- If all memory blocks are used up and no free memory blocks are available, the write operation is blocked, awaiting the release of a memory block.
Data Query Mechanism
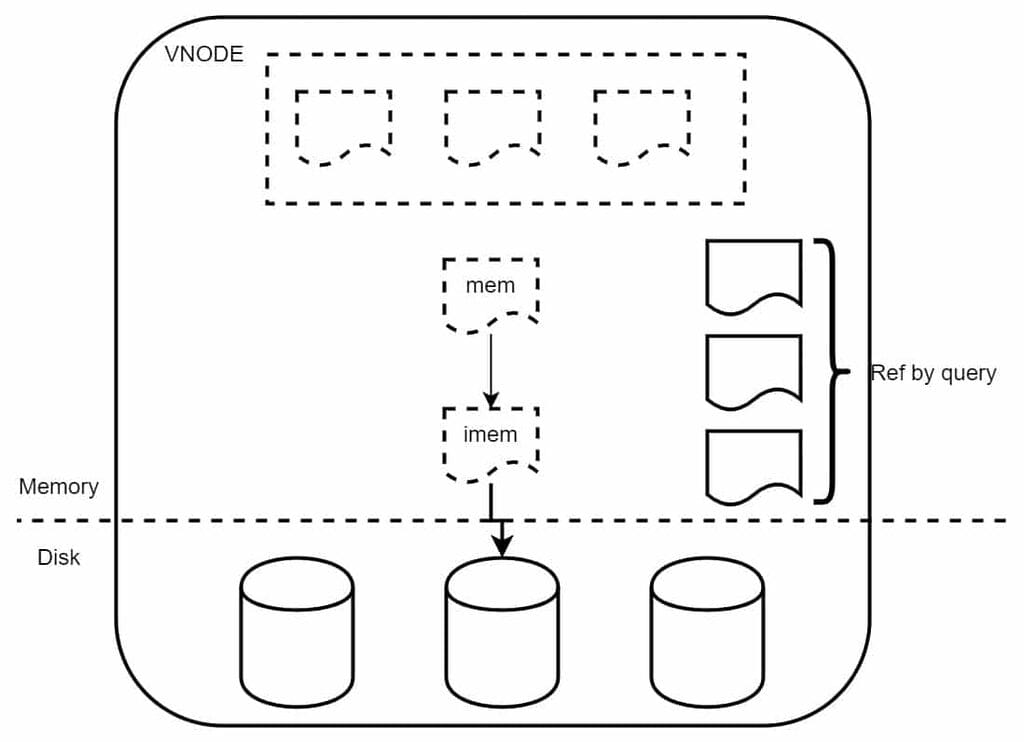
- Queries are executed in multiple batches, each returning a portion of data, and then waiting for the next data fetch request.
- The query result is a combination of memory (mem/imem) data and disk data.
- When a query begins, it takes a snapshot, referencing mem/imem and disk files.
- Upon query completion, it unreferences mem/imem. If the memory block’s reference count drops to zero, the block is returned to the free list.

The Long Query Problem
Most time-series data queries are short, such as querying the last record of a table/supertable or performing aggregate queries like count or sum. These queries quickly release MemTable resources for reuse, not affecting ongoing writes. However, issues arise with long-duration queries (e.g., queries exceeding an hour or a day). If multiple long queries occur simultaneously, all memory blocks in a Vnode can be occupied, leading to write stoppages.
Additionally, bugs in query code that fail to close query handles can result in prolonged mem/imem occupation, blocking writes. This issue has appeared in TDengine’s subscription and stream computing features.
Solution to the Long Query Problem
We need a solution that ensures writes are not blocked and long queries do not fail, even when many long queries are present or when user application code fails to close query handles promptly. The proposed solution is as follows:
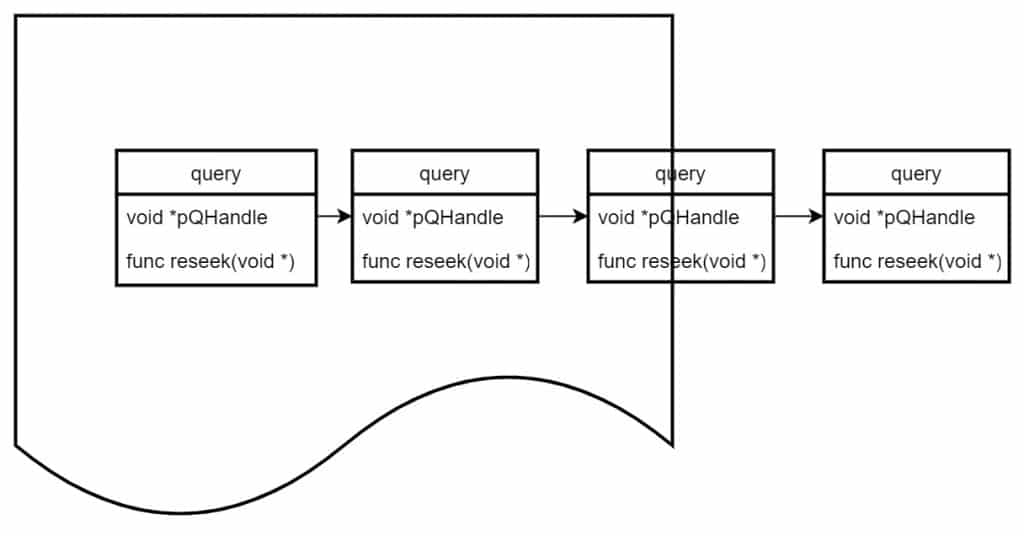
- When a query takes a snapshot, it registers the query handle to the memory blocks it occupies and registers a reseek function.
- When the query ends, it unregisters the handle from all occupied memory blocks.
- If a write operation finds no available memory blocks, it attempts to reclaim the oldest committed but still occupied memory block.
- During memory block reclamation, the write thread traverses all registered handles on that block, calling the reseek function.
- The reseek function locks the query handle if possible, sets the query handle to RESEEK state, saves the query state, and releases all occupied memory blocks.
- During its active cycle, the query thread locks the handle, checks for RESEEK state, retakes the snapshot, restores the query state, and continues querying.

Benefits of the Solution
- Writes can actively reclaim inactive query-occupied memory blocks, preventing prolonged write blockages.
- Long queries can resume by retaking snapshots and continuing querying, ensuring they do not fail.
Q&A
Q1: How to solve deadlock issues?
A: When reclaiming memory blocks, the write operation needs to lock the query handle registration list. In reseek callbacks, the query handle lock is also required, leading to potential deadlocks. To prevent this:
- Use trylock instead of lock: For write operations reclaiming memory blocks, trylock can attempt to acquire the query handle control, avoiding thread blockage and reducing deadlock risks.
- Multiple attempt mechanism: Combine trylock with multiple attempts to increase the chances of acquiring the lock, lowering deadlock risks.
Q2: Will long queries be continuously reseeked by writes, causing perpetual recovery?
A: No. Each query handle receives a version number when opened, indicating the latest data version written to the Vnode. A query can only see data versions up to this number. During snapshot taking, mem/imem data covered by this version number will be referenced by the query. As new data is written, new mem/imem data won’t be referenced by the long query, limiting RESEEK to at most twice per long query.

Conclusion
By optimizing the handling of long queries, TDengine can prevent long-duration queries from becoming a performance bottleneck. This ensures efficient concurrent writes and queries, maintaining system performance even in complex query scenarios.
