
This article uses the standard CTP market interface as an example. It assumes the data structure is CThostFtdcDepthMarketDataField.
Introduction
Before joining TDengine, the author Ding Bo, worked as a software engineer in Hongyuan Taiping Quantitative Investment. Having encountered this particular use case, with storing high frequency ticker data, he presents a solution that uses TDengine as a persistence mechanism and a time-series solution for financial data.
Memory Storage Solution
If your system only performs intraday real-time analysis, and the total number of monitored financial instruments (the collective term for contracts such as spot, futures, options hereinafter referred to as “contracts”) is not large, you can simply use memory storage. This is usually only necessary for UHF (Ultra High Frequency) trading systems. There are many options for in-memory storage, two of which are more common.
Two-level Map Scheme
The type of the first-level map is std::unordered_map, the key is InstrumentID, and the value is a pointer to the second-level map. The type of the second-level map is std::map, the key is the market timestamp, and the value is the market structure. (Note: The market timestamp needs to construct a millisecond value of type long based on the two fields of UpdateTime and UpdateMillisec). The underlying data structure of std::unordered_map is a hash table, and indexing by key is the fastest. The underlying data structure of std::map is a binary tree search tree, which can iterate all or a certain piece of data in strict order of key size. The advantage of this data structure is that one can very quickly find quotations returned by a contract at a certain point in time or a certain period of time. This becomes the basis for subsequent trading signal calculations.
#include "ThostFtdcUserApiStruct.h"
#include "ThostFtdcUserApiDataType.h"
#include <map>
#include <unordered_map>
using namespace std;
int main()
{
unordered_map<TThostFtdcInstrumentIDType, map<long, CThostFtdcDepthMarketDataField>*> tickData;
}Map + Array
Since the total number of standard tickers for each contract per day is fixed (except for individual exchanges), we can initialize an array in advance to store the ticks. Calculated at 2 ticks per second (every 500 milliseconds), the length of a standard market day is 28800. When a market notification is received, the market time to which the notification is closest, is assigned to that ticker. For example, if the market time is 9:50:20, 133 milliseconds, then it is assigned to 9:50:20 and 0 milliseconds. If the time between the two ticks before and after is greater than 500 milliseconds, it is necessary to fill in the point in the middle. This is a fairly standard operation while receiving market data. The advantages of doing this are:
- Trading strategies usually rely on standardized quotes to calculate trading signals, and it will save time to receive quotes and standardize them in one step.
- You can directly use the array subscript to index the market price corresponding to the time, and the time complexity of the search is O(1).
#include "ThostFtdcUserApiStruct.h"
#include "ThostFtdcUserApiDataType.h"
#include <unordered_map>
#include <array>
using namespace std;
int main()
{
unordered_map<TThostFtdcInstrumentIDType, array<CThostFtdcDepthMarketDataField, 28800>> tickData;
}Persistent Storage Solution
Whether you do UHF trading or not, it is necessary to persist the market data. Usually persistent storage is used for review and analysis. Under large data volumes, traditional storage solutions like MongoDB, MySQL, file-based storage will soon encounter both read and write performance bottlenecks. This makes them unsuitable for intraday calculations. In recent years, the emergence of Time-Series Databases (TSDB) has made it possible to use a storage solution for market data. An open-source time series database like TDengine with built-in cache, message queue and cluster function is an optimal solutions for storing market data. Below I will use TDengine as an example to introduce a persistent storage solution.
Download TDengine Database Server
In the download stage, different systems use different installation packages, Ubuntu systems use deb packages, and CentOS systems use RPM packages.
Install and Start
Ubuntu
sudo dpkg -i TDengine-server-2.6.0.1-Linux-x64.debCentOS
sudo rpm -ivh TDengine-server-2.6.0.1-Linux-x64.rpmAfter the installation is successful, the prompt information on how to start the TDengine Database will pop up automatically, just follow the operation.
Build Quotes
Since the structure of all quotations is the same, only one supertable is needed to build the quotation table. Each contract corresponds to a subtable and the InstrumentID is used as the subtable name, and the exchange code is used as a quotation label. For convenience, the following example contains only 4 quotation fields:
- Enter the taos command line
taosdata@tdform1:~$ taos Welcome to the TDengine shell from Linux, Client Version:2.6.0.1 Copyright (c) 2022 by TAOS Data, Inc. All rights reserved. taos>
- Execute the following statement
create database marketdata;
use marketdata;
create stable tick(
ts timestamp,
updatetime binary(9),
updatemillisec int,
askprice1 double,
bidprice1 double,
askvolume1 int,
bidvolume1 int
) tags (exchanged binary(9));- View table structure
taos> desc tick;
Field | Type | Length | Note |
=================================================================================
ts | TIMESTAMP | 8 | |
updatetime | BINARY | 9 | |
updatemillisec | INT | 4 | |
askprice1 | DOUBLE | 8 | |
bidprice1 | DOUBLE | 8 | |
askvolume1 | INT | 4 | |
bidvolume1 | INT | 4 | |
exchangeid | BINARY | 9 | TAG |
Query OK, 8 row(s) in set (0.000378s)
- Write quotes to TDengine
#include "ThostFtdcUserApiStruct.h"
#include "ThostFtdcUserApiDataType.h"
#include "taos.h"
#include "taoserror.h"
#include <iostream>
#include <sstream>
using namespace std;
void insertTickData(TAOS* taos, CThostFtdcDepthMarketDataField &tick) {
stringstream sql;
// A subtable will be created automatically - tick.InstrumentID
sql << "insert into " << tick.InstrumentID << " using tick tags("
<< tick.ExchangeID << ") values(now, '" << tick.UpdateTime << "', "
<< tick.UpdateMillisec << "," << tick.AskPrice1 << "," << tick.BidPrice1
<< "," << tick.AskVolume1 << "," << tick.BidVolume1 << ")";
TAOS_RES *res = taos_query(taos, sql.str().c_str());
if (res == nullptr || taos_errno(res) != 0) {
cerr << "insertTitckData failed," << taos_errno(res) << ", " << taos_errstr(res) << endl;
}
}
int main()
{
TAOS *taos = taos_connect("localhost", "root", "taosdata", "marketdata", 6030);
// Test data
CThostFtdcDepthMarketDataField tick;
strcpy_s(tick.InstrumentID, "IH2209");
strcpy_s(tick.UpdateTime, "14:10:32");
strcpy_s(tick.ExchangeID, "DEC");
tick.UpdateMillisec = 500;
tick.AskPrice1 = 123.8;
tick.BidPrice1 = 123.4;
tick.AskVolume1 = 10;
tick.BidVolume1 = 9;
// Write test data
insertTickData(taos, tick);
taos_close(taos);
}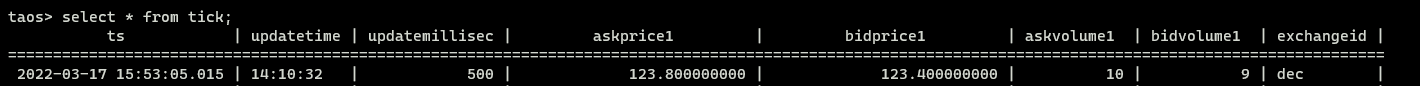
Query the Latest Market Data
TDengine has a cache function for the latest data of each table. There is no need to read the disk because the LAST function retrieves the data transparently.
#include "ThostFtdcUserApiStruct.h"
#include "ThostFtdcUserApiDataType.h"
#include "taos.h"
#include "taoserror.h"
#include <string>
#include <iostream>
using namespace std;
CThostFtdcDepthMarketDataField* getLastTick(TAOS* taos, const char* instrumentID) {
string sql("select last(*) from ");
sql += instrumentID;
TAOS_RES* res = taos_query(taos, sql.c_str());
if (res == nullptr || taos_errno(res) != 0) {
cerr << "getLastTick failed," << taos_errno(res) << ", " << taos_errstr(res) << endl;
return nullptr;
}
TAOS_ROW row = taos_fetch_row(res);
if (row == nullptr) {
return nullptr;
}
CThostFtdcDepthMarketDataField* tick = new CThostFtdcDepthMarketDataField();
//int64_t ts = *((int64_t*)row[0]);
memcpy(tick->UpdateTime, row[1], 9);
tick->UpdateMillisec = *(int*)row[2];
tick->AskPrice1 = *((double *)row[3]);
tick->BidPrice1 = *((double*)row[4]);
taos_free_result(res);
return tick;
}
int main() {
TAOS* taos = taos_connect("localhost", "root", "taosdata", "marketdata", 6030);
CThostFtdcDepthMarketDataField* tick = getLastTick(taos, "IH2209");
cout << "askPrice1=" << tick->AskPrice1 << " bidPrice1=" << tick->BidPrice1 << endl;
delete tick;
taos_close(taos);
}The above two sample programs show the methods of writing and querying. Combined with the built-in query function and aggregation functions of TDengine more complex functionality can by built:
- Use the four SQL functions of MAX, FIRST, MIN, and LAST to calculate the four price levels of high, open, low and close on the K line.
- Calculate the moving average price using the INTERVAL and SLIDING query clauses and the AVG function. No specific examples are given here, but you can refer to the official documentation .
Practical Experience
TDengine also has a very rich set of analysis functions which you can find in the official documentation. You can also find many use cases from customer who are doing data processing for quantitative investing.
For example the website HiThink Royal Flush receives massive amounts of market data every day from various exchanges. They have to ensure the accuracy of market data for their users. It is important to remember that portfolio management systems (PMS) need both real-time and historical market data. HiThink Royal Flush used Postgres+LevelDB as their data storage solution but there were frequent pain points. They mainly had the following two problems that they needed to solve urgently:
- Many dependencies and poor stability : As a multi-variety post-investment analysis service, PMS uses various daily real-time market data and relies on Http, Postgres, LevelDB and other databases for data acquisition . Too many data acquisition links reduce the reliability of the platform, and at the same time rely on other services, making the query problem too complicated.
- Performance can not meet the demand : As a multi-variety post-investment analysis, PMS requires a large number of market quotations on which they run various analysis algorithms. This takes up a lot of compute time and leads to a degradation in performance.
From the perspective of the business, there was an urgent need to find a better solution. Flush conducted research on data storage solutions such as ClickHouse, InfluxDB, and TDengine. Since the market data is in the form of bound timestamps, it is obvious that a time series database is the idea solution. Between InfluxDB and TDengine, TDengine has much higher write speeds than that of InfluxDB, the cluster version is open source and TDengine supports C /C++, Java, Python, Go and RESTful data interfaces, which made it the ultimate choice for flush.
The performance improvement after the migration to TDengine was very obvious. The following table shows the performance comparison in terms of query latency between the previous solution and after the migration to TDengine.
| Query | RESTful JDBC (ms) | JNI-JDBC (ms) | Previous Solution |
|---|---|---|---|
| 1 stock, 1 day | 9 | 5 | 117 |
| 1 stock, 1 year | 32 | 9 | 258 |
| 1 stock, 5 years | 83 | 29 | 700 |
| 8 stocks, 1 day | 11 | 7 | 116 |
| 8 stocks, 1 year | 120 | 60 | 1081 |
| 8 stocks, 5 year | 532 | 225 | 2492 |
After the transformation, the system was significantly more stable. Before the transformation, with a total of 400K calls to the database, there were a total of 0.01% anomalies. After the transformation, the anomalies were reduced to 0.001%.
On the TDengine website, you can find several blogs from users that describe their experiences with using TDengine in the financial sector. If you are in the financial sector and are experiencing problems with performance, cost or other issues with your current solution, or are looking to implement a new system, please get in touch with us.